
Here is a list of the most common reinforcement learning algorithms grouped by category.
1. Model-free RL algorithms
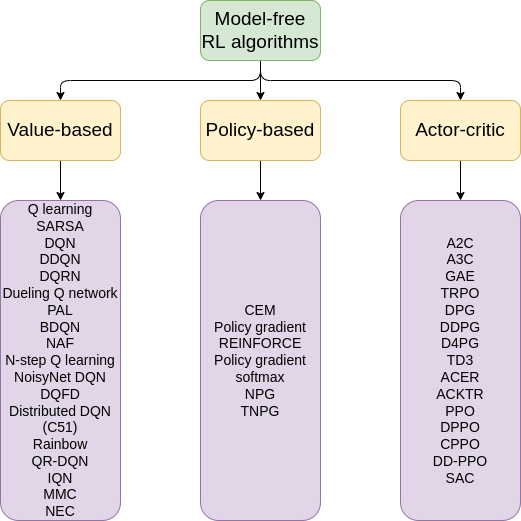
1.1. value-based
- Q-learning = SARSA max - 1992
- State Action Reward State-Action (SARSA) - 1994
- Deep Q Network (DQN) - 2013
- Double Deep Q Network (DDQN) - 2015
- Deep Recurrent Q Network (DRQN) - 2015
- Dueling Q Network - 2015
- Persistent Advantage Learning (PAL) - 2015
- Bootstrapped Deep Q Network - 2016
- Normalized Advantage Functions (NAF) = Continuous DQN - 2016
- N-Step Q Learning - 2016
- Noisy Deep Q Network (NoisyNet DQN) - 2017
- Deep Q Learning for Demonstration (DqfD) - 2017
- Categorical Deep Q Network = Distributed Deep Q Network = C51 - 2017
- Rainbow - 2017
- Quantile Regression Deep Q Network (QR-DQN) - 2017
- Implicit Quantile Network - 2018
- Mixed Monte Carlo (MMC) - 2017
- Neural Episodic Control (NEC) - 2017
1.2. Policy-based
- Cross-Entropy Method (CEM) - 1999
- Policy Gradient
- REINFORCE = Vanilla Policy Gradient (VPG) - 1992
- Policy gradient softmax
- Natural Policy Gradient (Optimisation) (NPG) / (NPO) - 2002
- Truncated Natural Policy Gradient (TNPG) - 2016
1.3. Actor-Critic
- Advantage Actor Critic (A2C) - 2016
- Asynchronous Advantage Actor-Critic (A3C) - 2016
- Generalized Advantage Estimation (GAE) - 2015
- Trust Region Policy Optimization (TRPO) - 2015
- Deterministic Policy Gradient (DPG) - 2014
- Deep Deterministic Policy Gradients (DDPG) - 2015
- Actor-Critic with Experience Replay (ACER) - 2016
- Actor Critic using Kronecker-Factored Trust Region (ACKTR) - 2017
- Proximal Policy Optimization (PPO) - 2017
- Distributed PPO (DPPO) - 2017
- Clipped PPO (CPPO) - 2017
- Decentralized Distributed PPO (DD-PPO) - 2019
- Soft Actor-Critic (SAC) - 2018
2. Model-based RL algorithms
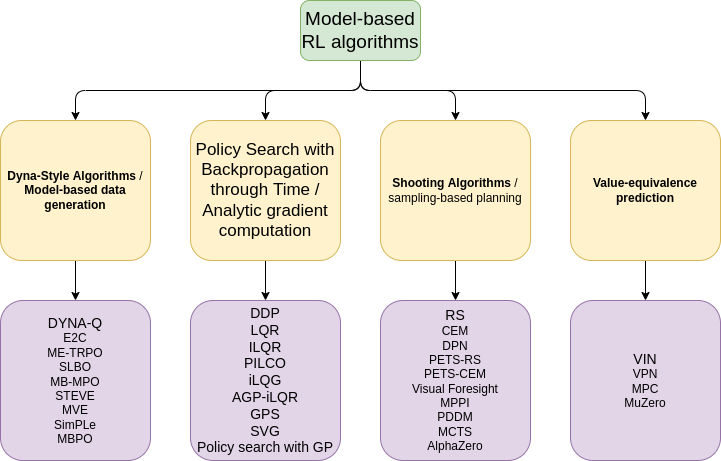
2.1. Dyna-Style Algorithms / Model-based data generation
- Dynamic Programming (DP) = DYNA-Q - 1990
- Embed to Control (E2C) - 2015
- Model-Ensemble Trust-Region Policy Optimization (ME-TRPO) - 2018
- Stochastic Lower Bound Optimization (SLBO) - 2018
- Model-Based Meta-Policy-Optimzation (MB-MPO) (meta learning) - 2018
- Stochastic Ensemble Value Expansion (STEVE) - 2018
- Model-based Value Expansion (MVE) - 2018
- Simulated Policy Learning (SimPLe) - 2019
- Model Based Policy Optimization (MBPO) - 2019
2.2. Policy Search with Backpropagation through Time / Analytic gradient computation
- Differential Dynamic Programming (DDP) - 1970
- Linear Dynamical Systems and Quadratic Cost (LQR) - 1989
- Iterative Linear Quadratic Regulator (ILQR) - 2004
- Probabilistic Inference for Learning Control (PILCO) - 2011
- Iterative Linear Quadratic-Gaussian (iLQG) - 2012
- Approximate iterative LQR with Gaussian Processes (AGP-iLQR) - 2014
- Guided Policy Search (GPS) - 2013
- Stochastic Value Gradients (SVG) - 2015
- Policy search with Gaussian Process - 2019
2.3. Shooting Algorithms / sampling-based planning
- Random Shooting (RS) - 2017
- Cross-Entropy Method (CEM) - 2013
- Model Predictive Path Integral (MPPI) - 2015
- Monte-Carlo Tree Search (MCTS) - 2006
- AlphaZero - 2017
2.4. Value-equivalence prediction
- Value Iteration Network (VIN) - 2016
- Value Prediction Network (VPN) - 2017
- Model Predictive Control (MPC) - 2018
- MuZero - 2019
3. Other RL algorithms
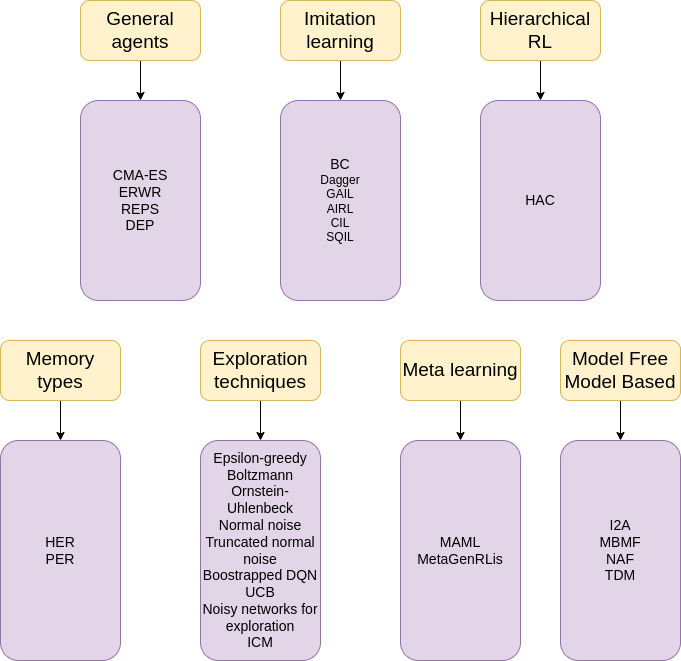
3.1. General agents
- Covariance Matrix Adaptation Evolution Strategy (CMA-ES) - 1996
- Episodic Reward-Weighted Regression (ERWR) - 2009
- Relative Entropy Policy Search (REPS) - 2010
- Direct Future Prediction (DFP) - 2016
3.2. Imitation learning
- Behavioral Cloning (BC)
- Dataset Aggregation (Dagger) (i.e. query the expert) - 2011
- Adversarial Reinforcement Learning
- Conditional Imitation Learning - 2017
- Soft Q-Imitation Learning (SQIL) - 2019
3.3. Hierarchical RL
3.4. Memory types
3.5. Exploration techniques
- E-Greedy
- Boltzmann
- Ornstein–Uhlenbeck process
- Normal Noise
- Truncated Normal Noise
- Bootstrapped Deep Q Network
- UCB Exploration via Q-Ensembles (UCB)
- Noisy Networks for Exploration
- Intrinsic Curiosity Module (ICM) - 2017
3.6. Meta learning
- Model-agnostic meta-learning (MAML) - 2017
- Improving Generalization in Meta Reinforcement Learning using Learned Objectives (MetaGenRLis) - 2020



Leave a comment