
Gym is a Python library maintained by OpenAI. It provides a standard interface to create and initialise training environments for reinforcement learning agents. It also provides a diverse collection of reference environments that represent general RL problems, which can be used to compare the performance of various RL algorithms. In this post, we will learn how to use it.
Installation
Gym can be installed as a pip package. In a terminal, type:
pip install gym
The Cart-Pole environment
The Cart-Pole environment is a classic RL problem which is provided as a default Gym environment.
This environment simulates an inverted pendulum where a pole is attached to a cart which moves along a frictionless track. At each time step, the agent can move the cart to the left or to the right. The pendulum starts upright, and the goal is to prevent it from falling over. Here’s a example.
The Cart-Pole problem has been successfully solved in a physical environment, as shown here.
Initialising the environment
Let’s start by creating the environment and by retrieving some useful information.
import gym
env = gym.make('CartPole-v0')
print(env.action_space)
print(env.observation_space)
print(env.observation_space.high)
print(env.observation_space.low)
The action space is discrete of size 2. There are 2 possible actions that can be performed at each time step: move the cart to the left (action: 0) or to the right (action: 1).
The observation space is continuous (Box) of size 4. An observation is an array of 4 numbers that characterise the state of the cart-pole at each time step: [cart position, cart velocity, pole angle, pole angular velocity]. The range values of the states are given below:
| Num | Observation | Min | Max |
|---|---|---|---|
| 0 | Cart Position | -4.8 | 4.8 |
| 1 | Cart Velocity | -Inf | Inf |
| 2 | Pole Angle | ~ -0.418 rad (-24°) | ~ 0.418 rad (24°) |
| 3 | Pole Angular Velocity | -Inf | Inf |
A reward of +1 is given for every time step that the pole remains upright and the cumulative reward is calculated at the end of the episode. The episode terminates if any one of the following occurs:
- Pole Angle is greater than ±12°
- Cart Position is greater than ±2.4 (center of the cart reaches the edge of the display)
- Episode length is greater than 200
The problem is considered solved when the average reward is greater than or equal to 195 over 100 consecutive trials.
Implementing a random policy
The goal of the problem is to identify which series of actions maximise the total cumulative reward at the end of an episode. For the sake of simplicity, we will start by implementing a random policy, i.e. at each time step, the cart is either pushed to the right or to the left randomly.
def policy1():
return env.action_space.sample()
We let the agent learn over 20 episodes of 100 time steps each.
nb_episodes = 20
nb_timesteps = 100
policy_nb = 3 # choose policy number here
cum_rewards = []
# ITERATE OVER EPISODES
for episode in range(nb_episodes):
state = env.reset()
episode_rewards = 0
# ITERATE OVER TIME-STEPS
for t in range(nb_timesteps):
if policy_nb == 1:
action = policy1()
elif policy_nb == 2:
action = policy2(t)
elif policy_nb == 3:
action = policy3(t)
state, reward, done, info = env.step(action)
episode_rewards += reward
if done:
print('Episode:{}/{} finished after {} timesteps | Total reward: {}'.format(episode, nb_episodes, t+1, episode_rewards))
break
# Append the episode cumulative reward to the reward list
cum_rewards.append(episode_rewards)
mean_cum_reward = sum(cum_rewards) / len(cum_rewards)
print("The mean of the cumulative rewards over {} episodes for policy {} is: {}".format(nb_episodes, policy_nb, mean_cum_reward))
env.close()
Of course, because we are only taking random actions, we can’t expect any improvement overtime. The policy is very naive here, we will implement more complex policies later. Here is an example of output:
Episode:0/20 finished after 13 timesteps | Total reward: 13.0
Episode:1/20 finished after 21 timesteps | Total reward: 21.0
Episode:2/20 finished after 14 timesteps | Total reward: 14.0
Episode:3/20 finished after 15 timesteps | Total reward: 15.0
Episode:4/20 finished after 20 timesteps | Total reward: 20.0
Episode:5/20 finished after 28 timesteps | Total reward: 28.0
Episode:6/20 finished after 29 timesteps | Total reward: 29.0
Episode:7/20 finished after 34 timesteps | Total reward: 34.0
Episode:8/20 finished after 14 timesteps | Total reward: 14.0
Episode:9/20 finished after 11 timesteps | Total reward: 11.0
Episode:10/20 finished after 42 timesteps | Total reward: 42.0
Episode:11/20 finished after 14 timesteps | Total reward: 14.0
Episode:12/20 finished after 18 timesteps | Total reward: 18.0
Episode:13/20 finished after 9 timesteps | Total reward: 9.0
Episode:14/20 finished after 10 timesteps | Total reward: 10.0
Episode:15/20 finished after 12 timesteps | Total reward: 12.0
Episode:16/20 finished after 23 timesteps | Total reward: 23.0
Episode:17/20 finished after 11 timesteps | Total reward: 11.0
Episode:18/20 finished after 23 timesteps | Total reward: 23.0
Episode:19/20 finished after 17 timesteps | Total reward: 17.0
Implementing a hard-coded policy
n the same effort to understand how to use OpenAI Gym, we can define other simple policies to decide what action to take at each time step. For example, instead of using a random policy, we can also hard-code the actions to take at each time steps. For example, we can impose the agent to push the cart to the left for the first 20 time steps and to the right for the other ones.
def policy2(t):
action = 0
if t < 20:
action = 0
else:
action = 1
return action
We can also decide to alternate left and right pushes at each time steps.
def policy3(t):
action = 0
if t%2 == 1:
action = 1
return action
Here is an animation of the cartpole where policy3 is applied.
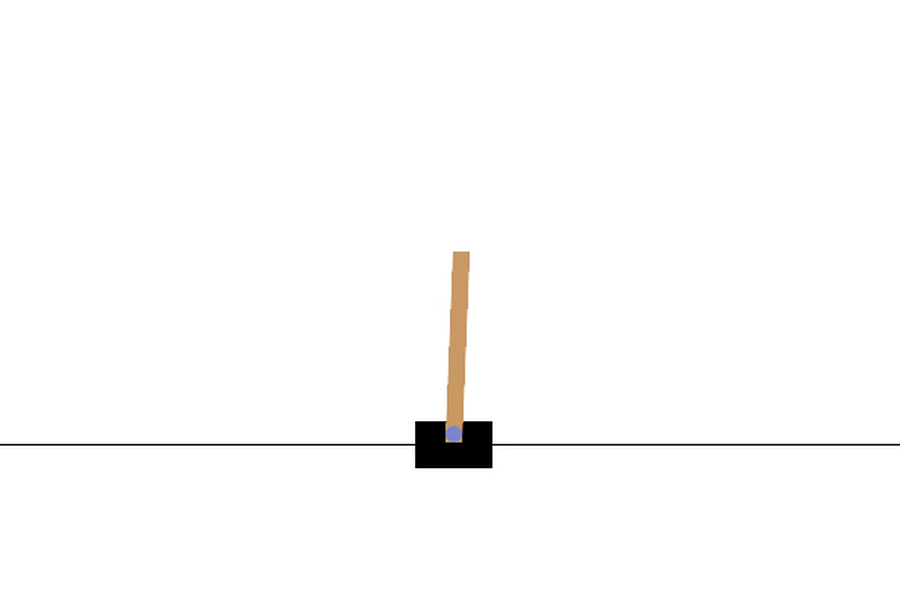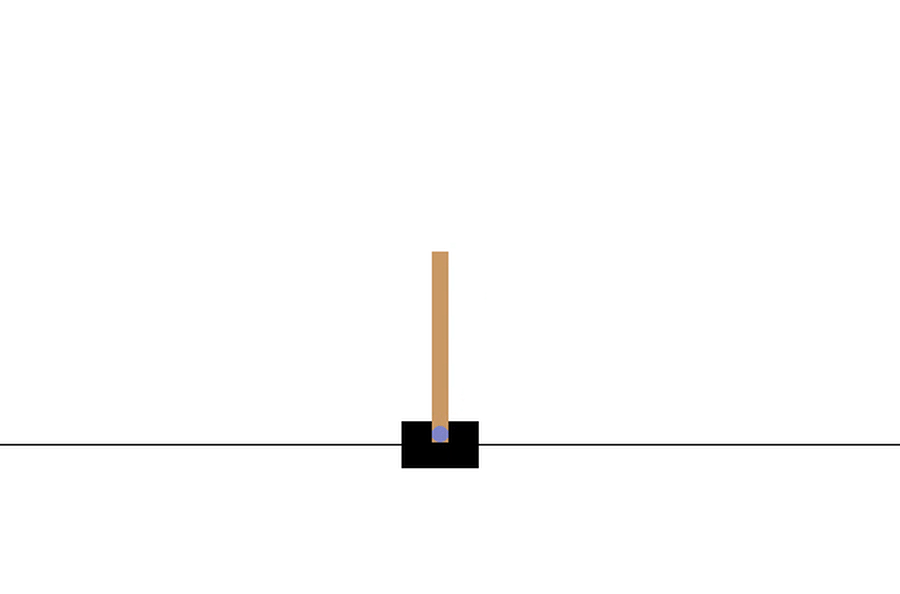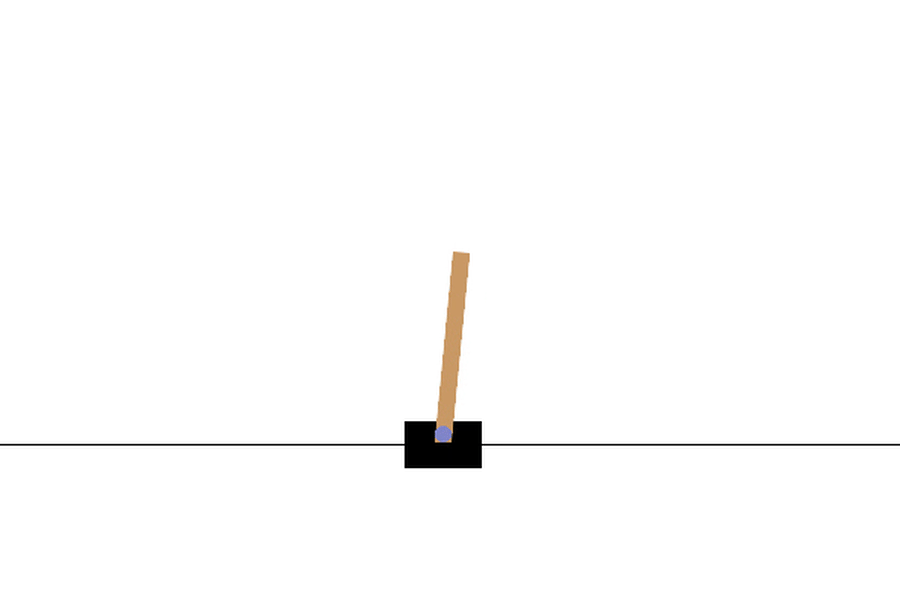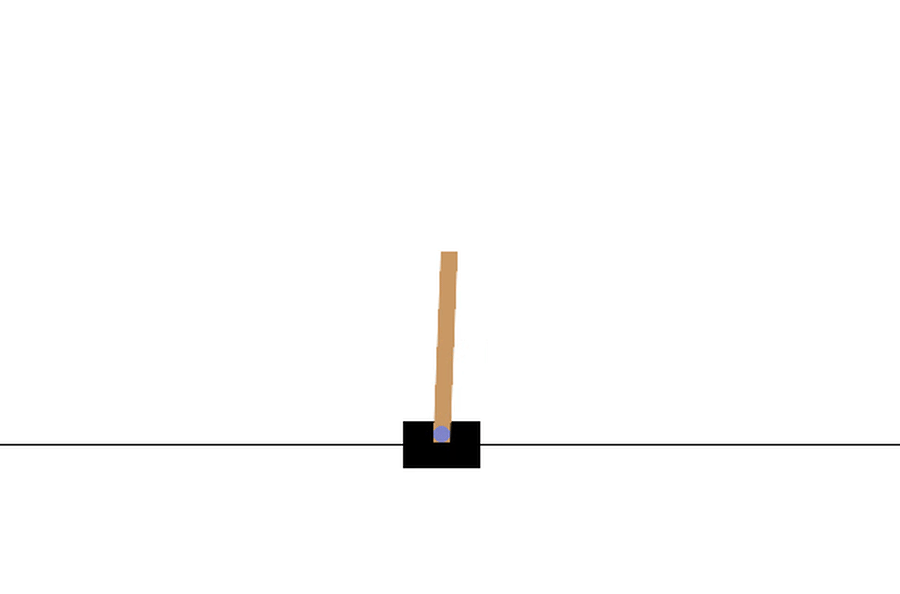
We can compare how well the various policies performed by comparing the average cumulated reward over the same number of episodes.
| Policy | Average cumulated reward over 20 episodes |
|---|---|
| Random | 18.9 |
| Hardcoded 1 | 9.3 |
| Hardcoded 2 | 36.9 |
The policy that performed the best is the one where we alternate pushed to the left and to the right, which could make sense intuitively when we consider the goal of balancing a pole. We can of course use more sophisticated policies, which we will see in future articles.
The code to run these examples yourself can be found here.
Conclusion
In this post, we learnt to initialise a Gym environment and to implement simple policies. In a later article I will explain how to define a more clever policy.



Leave a comment