
As we have seen before, RL agents must interact with an environment, either by sending an action or by receiving a reward or observation from this environment. Real-life environments are often impractical to train for safety or time-efficiency reasons. Therefore, a simulated virtual environment is often used in practice. For example in robotics, the training is usually performed on a virtual environment first before deploying it to the real robot. This saves a lot of time and wear-and-tear in physical robots.
OpenAI Gym is arguably the most popular virtual environment library in reinforcement learning. It offers a convenient interface between the agent and the environment. Gym makes it very easy to query the environment, perform an action, receive a reward and state or render the environment.
A wide range of toy benchmark environments are also implemented and are often used for comparing the performance of different RL algorithms. Example of such virtual environments include the cart-pole, mountain-car or inverted pendulum problems. These environments are great for learning, but eventually you will want to create a virtual environment to solve your own problem, be it for stock trading, robotics or self driving vehicles.
Gym integrates very nicely with physics engines, which allows researchers to create custom virtual environments for robotics tasks. One of the most used physics engine is MuJoCo (Multi-Joint dynamics with Contact). However, it requires a paid license, which can be an issue for some projects. That’s why in this post, I will focus on Pybullet, which is free and open source. (MuJoCo has a faster performance though, according to one of their own paper…).
This is the classical pipeline for training RL robotics agents.
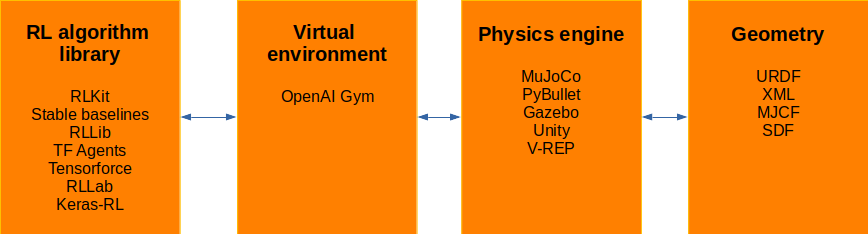
In this tutorial series, you will learn how to create custom virtual environments with a particular focus on robotics applications.



Leave a comment